The SDLC Strikes Back: Adapting to AI-Driven Development
Earlier this year, Lovable celebrated their biggest milestone yet - more than 12,000 (!) new projects created in a single day. The very next day, they went down. The irony? Their success became their downfall. Each new project in Lovable requires a new GitHub repository, and this surge - thousands per day - put such strain on GitHub’s infrastructure that it risked affecting GitHub’s entire platform. Their on-call engineer had to make the difficult decision to suspend Lovable’s account, effectively blocking all users from creating or editing their projects.
This incident perfectly illustrates a fundamental principle of systems thinking: when you push hard on one part of a complex system, it pushes back in unexpected ways. Peter Senge captured this insight in The Fifth Discipline as one of his laws of systems thinking: the harder you push, the harder the system pushes back.
The Software Development Lifecycle (SDLC) is one such complex system, and right now, we’re pushing on it harder than ever before. If you’re working with AI tools, you’ve probably experienced this yourself - code that used to take hours or days to write is now generated in seconds. “The code just writes itself now!” has become a common refrain in development circles. And while it’s not entirely wrong, it’s making us face some fascinating challenges.
What happens when code generation is no longer the bottleneck? Here’s what you’ll start seeing: larger PRs piling up in review queues, test suites taking longer to run, and deployments struggling to keep up. As we accelerate one part of the development cycle, the system inevitably responds in ways that demand our attention - and you’ll need to be ready.
Pipeline Pressure Points
As we accelerate code generation with AI, we’re seeing the system push back at both ends of our development pipeline - both before and after the actual build phase.
UX: The Pre-Build Bottleneck
Software development has always been constrained by implementation speed. Even at the 1968 conference where the term “Software Engineering” was coined, the word “cost” appears 96 times throughout the report - and they weren’t just talking about hardware. Despite decades of new methodologies, frameworks, and automation tools, writing code has remained stubbornly time-consuming.
But AI coding assistants are changing this equation dramatically. Tasks that used to take days - like scaffolding new APIs, building authentication systems or perfecting UI layouts - now take hours or minutes. The implementation speed that has bottlenecked our industry for decades is suddenly dramatically increasing.
And that’s when a new challenge emerges. I recently came across this Reddit post that hints at what’s coming:

Reddit post - Team transitioned to Cursor but bottleneck is now UX
While most teams are still focused on adopting AI for faster code generation, some early adopters are already hitting a different wall: they can implement features faster than they can design them. The bottleneck is shifting from implementation to conception - from how to build it to what to build.
This is systems thinking in action - as we optimise one part of the pipeline, we’re exposing constraints elsewhere. Soon, our biggest challenge won’t be writing code, but rather understanding user needs, designing intuitive interfaces, and crafting requirements that actually solve real problems. We’re going to need new ways to accelerate these early stages of development to keep pace with our AI-enhanced implementation capabilities.
The Speed Wobbles: Post-Build Challenges
Remember learning to ride a bike? There’s that terrifying moment when you’re going so fast that the handlebars start to shake. You’re not doing anything wrong - you’ve just hit that speed where everything starts to wobble. That’s exactly what’s happening in our development pipelines.
The ripple effects of accelerated code generation are showing up in unexpected places. As mentioned in a previous post, the 2024 DORA Report revealed a fascinating paradox: while AI tools are improving many of the things we typically associate with better delivery - documentation quality, code quality, code review speed, and reduced complexity - the industry is actually seeing a decline in overall delivery performance.
This highlights another key principle of systems thinking: improving individual components doesn’t necessarily improve the system as a whole. In fact, it can make things worse if those improvements aren’t balanced across the entire pipeline. The DORA findings suggest that our development processes, built and optimised over decades for human-speed code generation, need fundamental rethinking to handle the velocity that AI enables.
Adapting to AI-Driven Development
As these pressure points emerge, we’re seeing new tools and practices evolve to help us adapt. These adaptations focus on two key areas: how we provide context to our AI tools, and how we think about our source artifacts themselves.
The Importance of Context
Here’s a scenario every developer knows too well: you’re working with a new teammate, and they ask you how to use the company’s internal authentication library. You point them to the documentation, only to realise it’s woefully outdated. So you spend the next hour walking them through the codebase, explaining the patterns, the gotchas, and trying to recall why certain decisions were made.
Now imagine having this same conversation with an AI coding assistant. Without proper context, it’s just as lost as that new teammate. Sure, it can write decent code from simple prompts, but ask it to work with your custom libraries or follow your team’s patterns that it can’t possibly know anything about, and it’s flying blind.
This is why we’re seeing tools like LLMContext.com and Uithub.com emerge. These tools create rich, interpretable context files from your entire development ecosystem. Not just source code, but documentation in various formats - from Markdown files to PDFs, and even content from images and other media (thanks to Microsoft’s MarkItDown tool).
It’s like giving your AI assistant the equivalent of that hour-long walkthrough. Now when you ask it to add a feature using your authentication library, it understands the patterns, the constraints, and the team conventions. The code it generates isn’t just syntactically correct - it feels like it was written by someone who actually knows your codebase.
This emerging need for rich, well-structured context is yet another way the SDLC is pushing back. As our AI tools get better at writing code, we need better ways to help them understand our code.
Are Specs and Prompts our New Source Code?
Perhaps the most fundamental adaptation is in how we think about source code itself. When we were writing code by hand (wow, that feels weird to say), the most important thing to store safely was the source code. It’s in the name - source. From that, you should be able to derive everything else you need to know about how the system ought to operate.
The reality is that we’re not writing all the code by hand anymore. Instead, we’re writing specifications and prompts for AI coding assistants to generate code for us. And this raises an important question: if all you’re storing is the generated output of the LLMs, isn’t that almost the equivalent of only storing compiled code (bytecode, IL, binaries) instead of the source code?
We’re not in entirely new territory here. Test-Driven Development (TDD) and Behaviour-Driven Development (BDD) have long emphasized the importance of capturing the intent behind our code - TDD through tests, BDD through behaviour specifications. Both approaches ensure we’re clear about what we want before we build it. The same principle applies here - without capturing our intent, we’re just hoping the implementation does what we think it was intended to do.
The rise of AI-generated code raises interesting questions about code understanding. As AI generates more of our code, some worry we’ll lose our grasp on how it all works. But maybe that’s looking at it wrong - if we can capture and validate our intent clearly enough, debugging might become less about understanding the implementation and more about refining the specification. Think of it as hitting replay with a slightly modified script.
Following this line of thinking to its natural conclusion - if prompts and specifications are becoming our new source code, shouldn’t we treat them with the same care and organisation? Just as we’ve developed sophisticated ways to store, manage and share code, we need new tools and practices for managing our AI interactions. Here are three ideas that are already starting to emerge:
1. Prompt Libraries
Remember when we used to stash away useful code snippets? Those bits of tried-and-tested code that we’d copy-paste into new projects? For me it was SQL - I couldn’t help but keep almost every piece of SQL I ever wrote in a folder because you just never knew when it was going to come in handy again!
Well, welcome to the AI era’s equivalent: Prompt Libraries. Instead of storing code in repos, we’re now starting to store and share the prompts that consistently generate good outputs. We’re already seeing this materialize in practice - a recent article on dev.to highlights several emerging prompt libraries that are bringing engineering rigor to prompt creation and management.
Imagine having a library of prompts that you know will generate a solid REST API endpoint, complete with error handling and input validation. Or prompts that reliably create accessible React components following your team’s conventions. These proven prompts deliver predictable, high-quality results, just like the code libraries we’ve always relied on. We’re moving from sharing snippets on GitHub Gists to building entire ecosystems for testing, sharing, and versioning our most effective prompts.
This shift isn’t just about storing prompts - it’s about the emergence of prompt engineering as a crucial skill. My recent research revealed that 56% of software engineers see prompt engineering as highly important for their future role, while only 21% consider it unimportant.
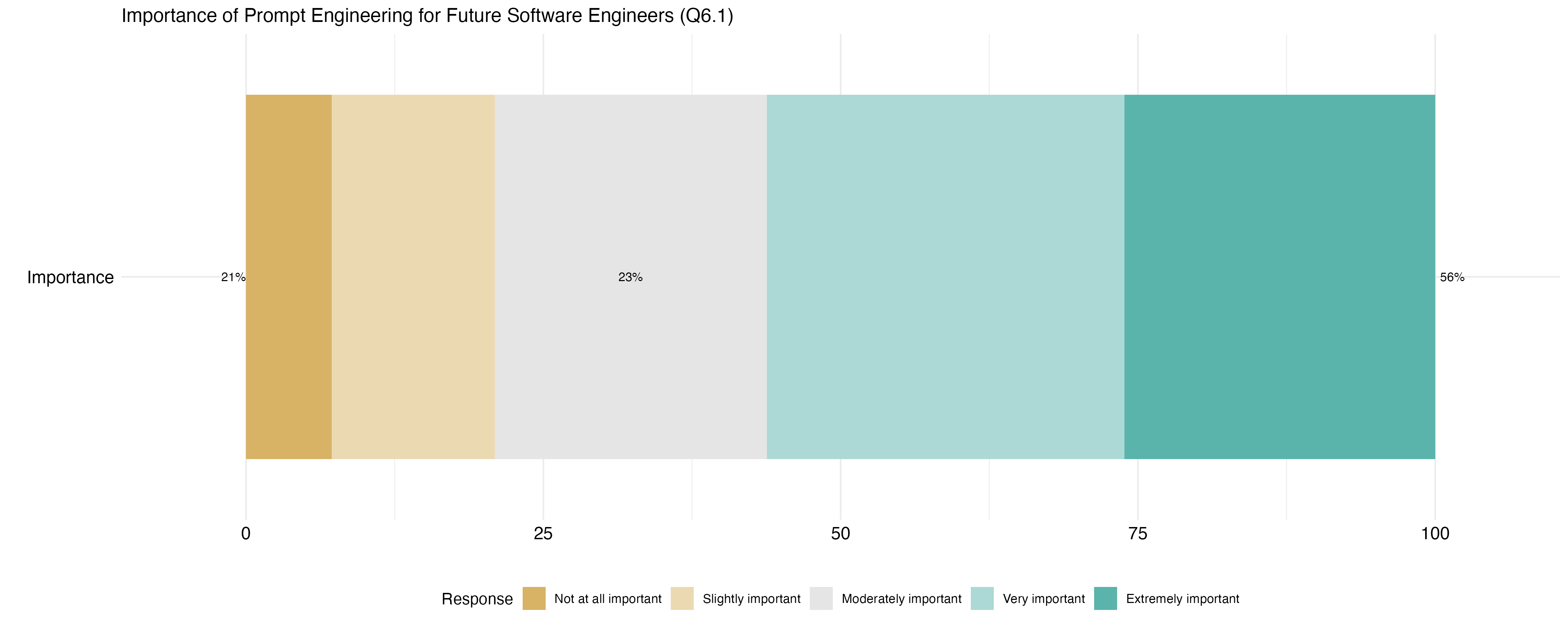
Future of Prompt EngineeringOver half of surveyed software engineers consider prompt engineering to be extremely or very important for their future role
2. Intent Records and Templates
Here’s another idea worth exploring: as AI increasingly generates our code, we need better ways to capture the reasoning behind implementation choices. I’m imagining something that I’m calling Intent Records - think of them like Architecture Decision Records (ADRs) but specifically designed for AI generation, capturing both what to build and why to build it that way.
An Intent Record could specify something like: “We need a caching layer that prioritises read speed over write speed because our analytics dashboard needs to handle 10,000 concurrent users viewing real-time data”. To standardise these records, we could develop Intent Templates - similar to how Detailed Design Documents (DDDs) structure their content - ensuring teams capture all necessary requirements, constraints, assumptions and design decisions that guide AI code generation.
3. Spec Modules
Building on this concept of structured documentation, here’s another idea to consider: what if we had reusable building blocks for creating AI-ready specifications? We could call them Spec Modules - pre-built specification components that describe in detail specific types of functionality. Need authentication? You’d grab a spec module that defines the security requirements, API endpoints, and user flows. Want a shopping cart? There’d be a module ready to customise with your specific business rules.
By breaking down specifications into these AI-friendly modules, you wouldn’t just be making your work more efficient - you’d be creating a new kind of component library. One that exists at a higher level than traditional code libraries, providing AI systems with clear, consistent instructions for generating reliable, production-ready code.
Rethinking the SDLC: AI is Pushing Back
For as long as software engineering has existed, we’ve been searching for ways to build better software with less pain. Faster builds, simpler deployments, shorter feedback loops. Every new methodology, every new tool, every process improvement - it’s all been about reducing friction and cognitive load in the development pipeline.
And now, AI coding assistants have done something remarkable. They’ve removed one of our longest-standing bottlenecks: the speed of writing code. It’s no longer a question of how fast we can build something - it’s a question of whether we can keep up with what we’re creating.
But software development isn’t just about writing code. It never was. The real work happens before the first line is written and long after the last commit. And now that we’ve uncapped code generation speed, we’re seeing pressure shift to everything around it - design, testing, review, deployment. The SDLC is pushing back.
In The Future of AI-Driven Software Engineering (Terragni et al., 2025), we explored where this shift is leading us. AI isn’t just accelerating development - it’s reshaping the way we build software altogether. Requirements need to be clearer. Design decisions and intent need to be explicit and recorded. Testing and validation need to scale. Our workflows, our tools, even our mental models of software engineering are being rewritten in real time. Our research suggests that AI itself might help address these emerging needs - from requirements analysis through to testing and deployment - though with varying levels of maturity across different stages of the lifecycle.
The implications are profound. The teams that understand and adapt to these system pressures now will be the ones that thrive in the AI era. As AI reshapes software development, it’s not just changing our tools - it’s transforming how we think about the entire discipline. The engineers who thrive in this new era will be those who excel at shaping intent, thinking in systems, and designing solutions that leverage both human insight and AI capabilities to build better software in ways we’re only beginning to imagine.